


AI Agents Aren't Failing. The Coordination Layer Is Failing.
There is a story circulating across boardrooms, conference stages, and tech blogs right now — and it goes something like this: AI agents showed up, promised the world, and quietly disappointed everyone. The models couldn't reason well enough. The automation was too brittle. The ROI never materialised.

The Narrative Getting It Wrong
There is a story circulating across boardrooms, conference stages, and tech blogs right now — and it goes something like this: AI agents showed up, promised the world, and quietly disappointed everyone. The models couldn't reason well enough. The automation was too brittle. The ROI never materialised.
That story is wrong. And at vThink, we think it is important to say so plainly.
AI agents are not failing. The coordination layer built around them is.
This distinction is not just semantic. It determines where organisations invest their energy, where engineering teams focus their debugging, and whether enterprises ever graduate from expensive pilots to production-grade automation. Getting this diagnosis wrong means spending millions fixing the wrong part of the stack.
What the Data Actually Says
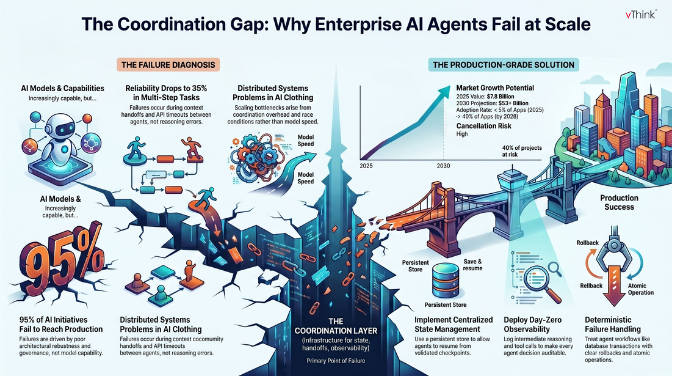
The numbers tell a striking story — if you know how to read them.
A recent MIT report found that 95% of AI initiatives fail to reach production — not because models lack capability, but because systems lack architectural robustness, governance structure, and integration depth. Separately, Gartner has predicted that more than 40% of agentic AI projects will be cancelled by 2027, citing the unanticipated complexity of scaling and poor risk controls.
Meanwhile, Carnegie Mellon benchmarks show that leading AI agents complete only 30–35% of multi-step tasks reliably. That sounds damning — until you examine why those tasks fail. The failure mode is almost never "the model couldn't reason." It is almost always: the model couldn't get reliable context from the previous agent, the handoff between workflow steps broke silently, a downstream API timed out and nothing caught it, or two agents wrote conflicting outputs into a shared state no one was monitoring.
The individual agents work. The system around them does not.
The Coordination Layer: What It Is and Why It Breaks
When engineers talk about a "coordination layer," they mean everything that sits between individual AI agents and a working production system: the orchestration logic, state management, inter-agent communication protocols, error recovery, observability, and governance controls.
In a single-agent application — a customer service chatbot, an AI writing assistant — coordination is trivial. There is one agent, one task, one output. But the moment organisations begin building multi-agent systems where a research agent feeds a summarisation agent that triggers a drafting agent that routes to an approval agent, the coordination layer becomes the most complex and failure-prone component in the entire system.
Here is how coordination breaks in practice.
State fragmentation. When Agent A completes its work and passes context to Agent B, that context handoff is rarely robust. Most platforms treat agents as independent tools with APIs to trigger and retrieve outputs. They do not maintain a centralised state that persists across agent handoffs. When Agent C fails 80% of the way through a task, the workflow crashes — and restarts from zero rather than resuming from the last stable checkpoint. Deloitte's 2025 analysis of enterprise AI implementations named "state management and failure recovery" as the most common technical barriers preventing pilots from reaching production.
Cascading failure propagation. In a distributed multi-agent workflow, an error in one agent does not stay contained. It amplifies. A hallucination at step three becomes a confident but incorrect input at step four, which corrupts the output at step five. By the time a human reviews the final result, tracing the failure back to its origin requires untangling every intermediate decision the system made. Most teams cannot do this because they built their observability infrastructure as an afterthought.
Race conditions and coordination overhead. As teams scale their multi-agent systems, the coordination overhead between agents becomes the bottleneck — not the individual model calls. Agents wait for other agents. Async pipelines develop race conditions. Orchestration patterns that work cleanly at 100 requests per minute fall apart completely at 10,000. These are not AI problems. They are distributed systems problems wearing AI clothing.
Lack of communication standards. Until recently, there was no standardised way for agents built on different platforms to communicate with each other. Two agents from two different vendors could not share context, coordinate tasks, or verify each other's outputs without custom integration work. The release of Anthropic's Model Context Protocol (MCP) and Google's Agent-to-Agent (A2A) protocol in 2024 and 2025 began addressing this, but enterprise adoption is still in early stages. Most production systems are still built on proprietary, fragile communication bridges that break silently.
The Prototype-to-Production Cliff
Every engineering team that has shipped AI agents at scale describes the same experience: picking a framework took two weeks; building a production-grade system took six months. The gap between a working prototype and a reliable production deployment is not about model intelligence. It is entirely about the infrastructure layer.
As one engineering lead put it in a 2025 production debrief: "The framework is a skeleton. The production-grade agent system is everything you build around that skeleton."
The frameworks — LangGraph, AutoGen, CrewAI — are genuinely useful for prototyping. They abstract away orchestration syntax and help teams get to a working demo quickly. But the hard problems they leave unsolved are the ones that matter in production: what happens when a tool returns garbage, how does the system handle a long workflow that fails at step 47, when should the agent escalate to a human, and how do you audit every decision the system made for compliance purposes?
These questions are not answered by choosing a better language model. They are answered by investing seriously in the coordination layer.
Where vThink Sees the Real Opportunity
At vThink, we have been watching this pattern play out across enterprise software for the last two years. The organisations that succeed with agentic AI are not the ones with access to the most powerful models. They are the ones that build the most disciplined coordination infrastructure.
The key investment areas that consistently separate successful production deployments from expensive pilots are worth examining directly.
Centralised state management means the entire workflow context lives in a single, persistent store that every agent can read from and write to. When a step fails, the system resumes from the last validated checkpoint rather than restarting. When an agent needs context from three earlier steps, it pulls from a consistent source rather than a fragmented handoff chain.
Observability from day one means that every decision point in every agent workflow is logged, traceable, and auditable. Not just input and output, but the intermediate reasoning, the tools called, the tools rejected, and the confidence at each step. You cannot debug what you cannot see, and teams that retrofit observability after deployment spend months untangling problems that could have been visible from the start.
Deterministic failure handling means treating multi-step agent workflows the way traditional databases treat transactions — with atomicity, rollback mechanisms, and idempotent tool calls. When an agent crashes mid-operation, the system must be able to roll back to a consistent state rather than leaving corrupted partial outputs behind. This is infrastructure engineering, not prompt engineering.
Governance and access controls mean that the same role-based permissions governing what a human employee can access must propagate to every agent operating on that employee's behalf. Without this, an AI agent becomes the weakest link in your enterprise security posture — capable of accessing data no human in its position would be permitted to see.
The Coordination Standard Is Emerging — But Slowly
The good news is that the industry is converging on answers. MCP standardised how agents connect to tools and external data sources. A2A began defining how agents from different platforms communicate with each other. The Linux Foundation's Agentic AI Foundation, launched in late 2025, is working to establish shared standards and governance frameworks — the agentic equivalent of what the World Wide Web Consortium did for the open web.
Gartner predicts that by the end of 2026, 40% of enterprise applications will embed task-specific AI agents, up from less than 5% in 2025. IDC expects AI copilots to be embedded in nearly 80% of enterprise workplace applications by 2026. The market is moving fast — projected to grow from $7.8 billion in 2025 to over $52 billion by 2030.
But Deloitte's analysis adds an important caveat: more than 40% of today's agentic AI projects could be cancelled by 2027 if enterprises fail to address the coordination and orchestration challenges preemptively. The technology window is open. The architectural debt window is closing.
What Enterprise Teams Should Do Now
The practical implications for engineering and product teams are clear.
Do not evaluate AI agent platforms based on model benchmarks alone. Evaluate them on the quality of their coordination infrastructure: state persistence, failure recovery, observability tooling, and governance controls. A platform with excellent reasoning and poor connectivity produces expensive pilots. A platform with robust orchestration produces scalable production automation.
Invest in observability before you invest in capability. Every production agent deployment that has gone well did so because the team could see exactly what the agent was doing, why it made each decision, and where it failed. Invest in tracing infrastructure from the first sprint, not the last.
Design for atomicity from the start. Treat every multi-agent workflow as a transaction. Define what a safe rollback looks like before you define what success looks like.
Build the governance layer in parallel with the agent layer. Access controls, audit trails, and escalation paths are not features to add after launch. They are design requirements that shape architecture from the beginning.
The Bottom Line
AI agents are genuinely capable. The large language models powering them have crossed a threshold where they can reason across complex, multi-step tasks in ways that create real business value. The hype, for once, is not entirely misplaced.
What is misplaced is the assumption that deploying capable agents is sufficient. It is not. An orchestration layer that cannot maintain state, recover from failures, communicate reliably between agents, and provide visibility into every decision is not a coordination layer. It is a liability.
At vThink, we build software that takes the coordination challenge seriously — because we believe that the enterprises that will lead the agentic era are not the ones with the most agents. They are the ones with the most disciplined infrastructure connecting those agents.
The agents are ready. The question is whether your coordination layer is.